Interesting CV Papers
选出来的论文好多都是3D😂😂😂
ICCV2025
-
Why LVLMs Are More Prone to Hallucinations in Longer Responses: The Role of Context
对LLVMs模型的幻觉缺陷进行深入研究,探索产生幻觉的原因,并给出了一些抑制幻觉的方法
CVPR2023-2025
-
Uni4D: Unifying Visual Foundation Models for 4D Modeling from a Single Video
Uni4D:从一个视频统一用于4D建模的视觉基础模型
Author: David Yifan Yao
Affiliation: University of Illinois at Urbana-ChampaignWe introduce Uni4D, a multi-stage optimization framework that harnesses multiple pretrained models to advance dynamic 3D modeling, including static/dynamic reconstruction, camera pose estimation, and dense 3D motion tracking.
主要是4D场景理解,对相机角度/姿态有分析
-
The Language of Motion: Unifying Verbal and Non-verbal Language of 3D Human Motion
Author: Changan Chen
Affiliation: Stanford UniversityIn this paper, we propose a novel framework that unifies verbal and non-verbal language using multimodal language models for human motion understanding and generation.
多模态语言理解
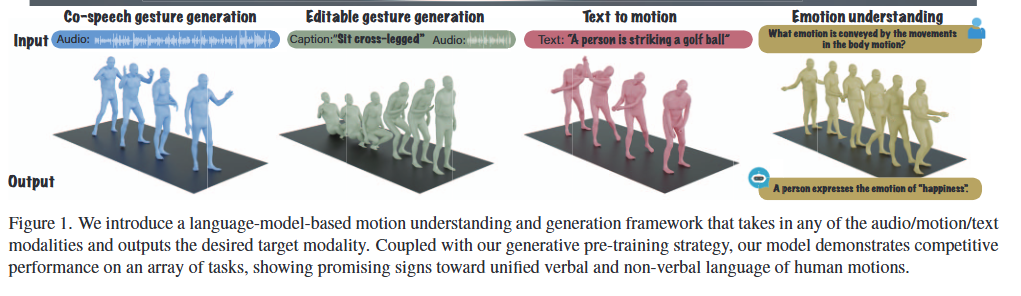
-
CALICO: Part-Focused Semantic Co-Segmentation with Large Vision-Language Models
基于LVLM的局部语义协同分割
Author :Kiet A. Nguyen
Affiliation: University of Illinois Urbana-Champaign

挺有意思的,对物体组成部分进行分割/理解有助于多图像理解,但不知道在3D场景/视频理解中能否实现?
-
Words or Vision: Do Vision-Language Models Have Blind Faith in Text?
VLMs是否盲目相信文本?
Author: Ailin Deng
Affiliation: National University of SingaporeVLMs disproportionately trust textual data over visual data when inconsistencies arise, leading to significant performance drops under corrupted text and raising safety concerns.
关于视觉与文本输入不一致时产生的问题/原因/解决方法
在受损文本下模型性能显著下降,因此要找到合适的方法去平衡文本与视觉输入 -
Multi-Layer Visual Feature Fusion in Multimodal LLMs: Methods, Analysis, and Best Practices
Author: Junyan Lin
Affiliation:…侧重于多层视觉特征,这个需要再了解一下
-
Evaluating Vision-Language Models as Evaluators in Path Planning
评估视觉语言模型作为路径规划评估器Author: Mohamed Aghzal
Affiliation: George Mason University, 2Carnegie Mellon University, 3National Science Foundation“Motivated by the intuition that “evaluation is easier than generation”
We introduce PATHEVAL, a novel benchmark evaluating VLMs as plan evaluators in complex path-planning scenarios.让VLM去评估规划的路径而不是规划路径
-
Author: Ao Wang
Affiliation: THUIt can efficiently capture a wide range of perceptual information and achieve precise feature aggregation for dynamic and complex visual representations, thus enabling proficient processing of visual information.
侧重于轻量级的视觉网路设计,挺有前景的
-
VideoDirector: Precise Video Editing via Text-to-Video Models
Author: Yukun Wang
Affiliation: Shenzhen Campus of Sun Yat-sen University, Sun Yat-sen University, THU, National University of Defense Technology

we propose a spatial-temporal decoupled guidance (STDG) and multi-frame null-text optimization strategy to provide pivotal temporal cues for more precise pivotal inversion.时空解耦
图我看懂了,感觉很厉害,但摘要没看太懂,总之就是文章有一些方法,能够保持复杂时空布局(spatial-temporal layout ),然后这个方法在各方面都优于现有技术
-
Instruction-based Image Manipulation by Watching How Things Move
Author: Mingdeng Cao
Affiliation: The University of Tokyo, Adobe可以仔细看看这篇,T2I

-
CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models
Author: Qingqing Zhao
Affiliation: NVIDIA ,Stanford University ,MIT
VLA(视觉语言动作)In this paper, we introduce a method that incorporates explicit visual chain-of-thought (CoT) reasoning into vision-language-action models(VLAs) by predicting future image frames autoregressively as visual goals before generating a short action sequence to achieve these goals
性能很强
-
Motion-Grounded Video Reasoning: Understanding and Perceiving Motion at Pixel Level
基于运动的视频推理:理解和感知像素级的运动
Author: Andong Deng
Affiliation: CRCV, University of Central Florida, 2University of Western Australia,3UNC, Chapel Hill, 4Amazon Web Services, 5 The University of Texas at Dallas运动理解,视频推理,但摘要没看懂
-
Learning Visual Generative Priors without Text
Author: Shuailei Ma
Affiliation: College of Information Science and Engineering, Northeastern University, Shenyang 110819, China2 Ant Group 3 Shanghai Jiao Tong University 4 Alibaba Group 5 HKUSTstudy image-to-image (I2I) generation
-
AirRoom: Objects Matter in Room Reidentification
Author: Runmao Yao
Affiliation: Spatial AI & Robotics (SAIR) Lab, University at Buffalo侧重于房间(室内)的识别
-
AdaCM^2: On Understanding Extremely Long-Term Video with Adaptive Cross-Modality Memory Reduction
基于自适应跨模态记忆缩减的超长视频理解
Author: Yuanbin Man
Affiliation: University of Texas, University of Georgia, University of Houston关注理解长时视频,具体方法还得看看全文
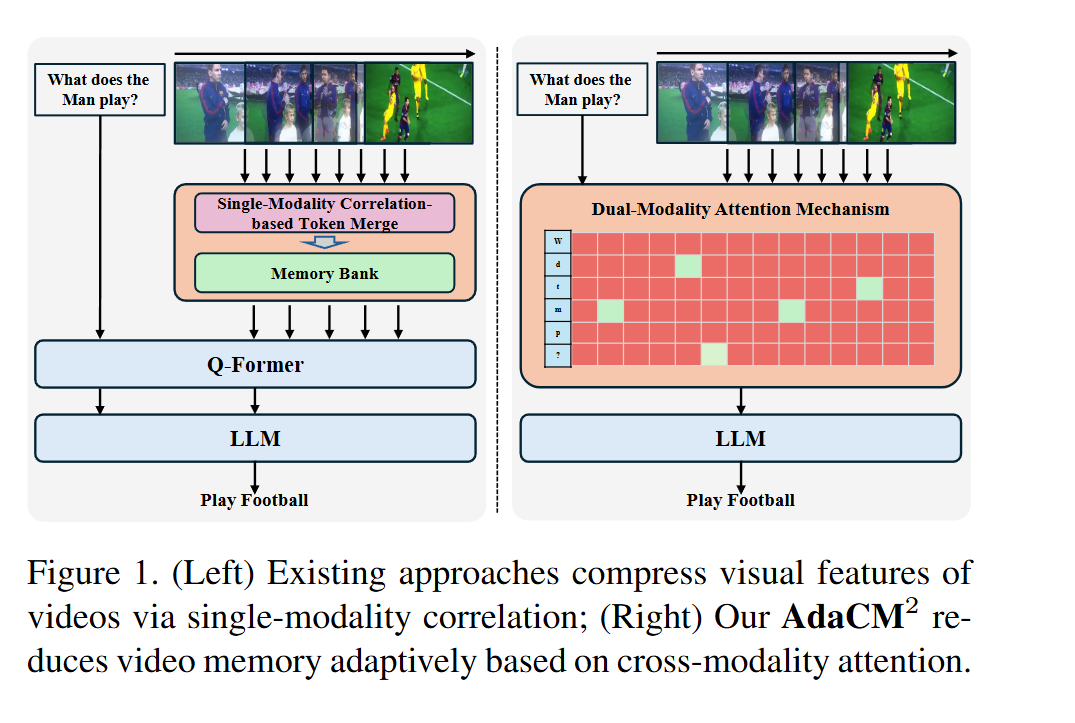
-
BOLT: Boost Large Vision-Language Model Without Training for Long-form Video Understanding
无需训练的大型视觉语言模型用于长格式视频理解
Author: Shuming Liu
Affiliation: King Abdullah University of Science and Technology提出了一种新的长视频采样方法: BOLT
a method to BOost Large VLMs without additional Training through a comprehensive study of frame selection strategies.Our results show that inverse transform sampling yields the most significant performance improvement, increasing accuracy on the Video-MME benchmark from 53.8% to 56.1% and MLVU benchmark from 58.9% to 63.4%.
-
RoboPEPP:基于视觉的机器人姿态和关节角度估计方法
Author: Raktim Gautam Goswami
Affiliation: New York University Tandon School of Engineering ,New York University Courant Institute of Mathematical Sciences ,Meta-FAIR通过视觉来感知机器人的姿态,未来可能在机器人协作中有应用
-
Perception Tokens Enhance Visual Reasoning in Multimodal Language Models
Author: Mahtab Bigverdi
Affiliation: University of Washington, Google Research与3D推理有关,可以仔细看看
To address this, we introduce Perception Tokens, intrinsic image representations designed to assist reasoning tasks where language is insufficient.
-
LSceneLLM: Enhancing Large 3D Scene Understanding Using Adaptive Visual Preferences
Author: Hongyan Zhi
Affiliation: South China University of Technology, Tencent Robotics X, Northeastern University,UMass Amherst, Pazhou Laboratory, Sichuan University
3D场景理解,根据任务生成视觉偏好,从而过滤冗余的视觉信息
Author: Hong-Xing Yu
Affiliation: Stanford University ,MIT
3d场景生成
-
Scene Splatter: Momentum 3D Scene Generation from Single Image with Video Diffusion Model
Author: Shengjun Zhang
Affiliation: Tsinghua University, WeChat Vision, Tecent Inc
3d场景生成, 从单个图像生成3D场景 -
Video-3D LLM: Learning Position-Aware Video Representation for 3D Scene Understanding
Author: Duo Zheng
Affiliation: The Chinese University of Hong Kong
3D 场景理解By treating 3D scenes as dynamic videos and incorporating 3D position encoding into these representations, our Video-3D LLM aligns video representations with real-world spatial contexts more accurately.
-
Text-guided Sparse Voxel Pruning for Efficient 3D Visual Grounding
Author: Wenxuan Guo
Affiliation: THU, 南洋理工
3d 视觉定位(与文本有关),提出了 text-guided pruning (TGP) and completion-based addition (CBA),以高效的方式深度融合3D场景表示和文本特征 -
Motion Prompting: Controlling Video Generation with Motion Trajectories
Author: Daniel Geng
Affiliation: Google DeepMind ,University of Michigan ,Brown University主要通过分析运动轨迹来生成视频,即”与图像交互“
-
Efficient Depth Estimation for Unstable Stereo Camera Systems on AR Glasses
Author: Yongfan Liu
Affiliation: University of California, Irvine应用于VR眼镜,降低推理延迟
-
Author: Sangmin Lee
Affiliation: Soongsil University提出了一个diffusion-based framework (DynScene) 直接从文本指令生成动态操作场景,从单个静态配置生成多个多样化的轨迹,实现生成速度更快,准确度更高
-
Author: Chengyue Wu
Affiliation: DeepSeek-AIwe decouple visual encoding into separate pathways, while still leveraging a single, unified
transformer architecture for processing. The decoupling not only alleviates the conflict between the visual encoder’s roles in understanding and generation, but also enhances the framework’s flexibility得先学习视觉编码后再仔细看
-
DrVideo: Document Retrieval Based Long Video Understanding
DrVideo:基于文档检索的长视频理解Author: Ziyu Ma
Affiliation: 湖南大学 Data Science & AI Department, Faculty of IT, Monash University把长视频理解转换为长文档理解任务,同样,得看看这种方法的缺陷(我觉得这个用于概括长视频应该没问题,但如果检索视频中的信息或知识,可能会遗漏)
-
Author: Martin Spitznagel
Affiliation: IMLA, Offenburg University Herrenknecht AG Mannheim University主要是提出问题,分析问题,但生成的结果显示出再物理正确性方面有很大局限性
i) are generative models able to learn complex physical relations from input-output image pairs?
ii) what speedups can be achieved by replacing differential equation based simulations?
-
WiLoR: End-to-end 3D Hand Localization and Reconstruction in-the-wild
WiLoR:端到端的 3D 手部定位和野外重建Author: Rolandos Alexandros Potamias
Affiliation: Imperial College London Shanghai Jiao Tong University从单目视频中实现3D手部跟踪,使用a real-time fully convolutional hand localization and a high-fidelity transformer-based 3D hand reconstruction model.
-
Author: Xin Zhang
Affiliation: National University of Singapore ASUS Intelligent Cloud Services如题,基于Mamba框架结合VFMs,VLMs ,需要有基本知识后再来读这篇文章
-
Author: Pedro Hermosilla Christian Stippel Leon Sick
Affiliation: TU Wien Ulm University扩展自监督方法在3D场景中的运用
our model is trained natively in 3D with a novel self-supervised approach based on a Masked Scene Modeling objective, which reconstructs deep features of masked patches in a bottom-up manner and is specifically tailored to hierarchical 3D models.
-
Author: Ming Li1
Affiliation: University of Tokyo这个是我想要研究的方向之一,目前LLMs,LMMs,在电子电路中的理解还很有限,这篇论文解释了LMMs的局限性,这个要仔细看一看
-
Author: Jihan Yang
Affiliation: 纽约、耶鲁、斯坦福探究MLLMs的视觉空间智能,同样是感兴趣的方向,要仔细看
-
Author: Cheng Chen
Affiliation: 南洋理工这个其实挺有意思,用计算机视觉去辅助建模,要看看如何实现
-
Lifting Motion to the 3D World via 2D Diffusion
通过 2D 扩散将运动提升到 3D 世界Author: Jiaman Li
Affiliation: 斯坦福思路挺好,但是这种2D的姿态图像要如何生成,还是说以及有相应的数据集?这张图上显示了2D-3D效果很好,但是需要看看2D图像的来源。
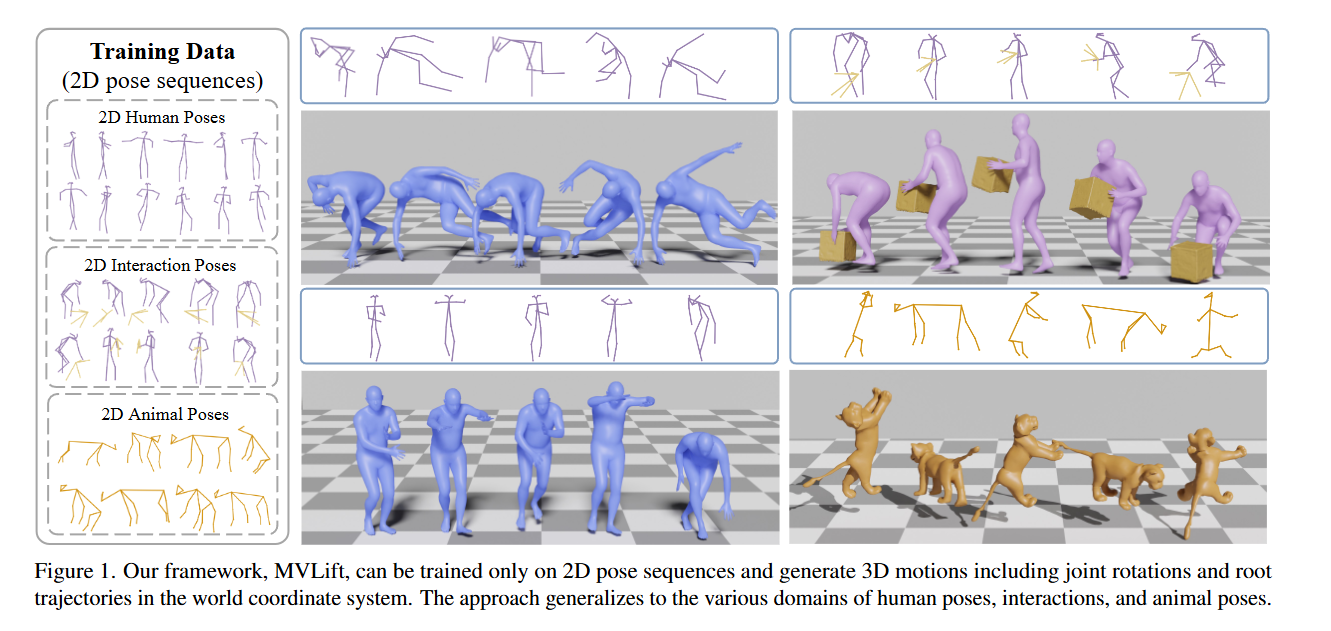
-
M-LLM Based Video Frame Selection for Efficient Video Understanding
基于 M-LLM 的视频帧选择,实现高效的视频理解Author: Kai Hu
Affiliation: Carnegie Mellon University University of Central Florida Amazon长视频采样策略,是感兴趣的方向
In order to train the proposed frame selector, we introduce two supervision signals
(i) Spatial signal, where single frame importance score by prompting an M-LLM;
(ii) Temporal signal, in which multiple frames selection by prompting Large Language Model (LLM) using the captions of all frame candidates.
-
Author: Yancheng Cai, Fei Yin, Dounia Hammou, Rafal Mantiuk
Affiliation: 剑桥这是一个很好的问题,要仔细看看,之前问过智能感知老师关于垃圾分类的问题,当时老师给我一个解释是:如果人眼识别不出这个垃圾是什么(指可能被污渍遮挡后看不清),那计算机就无法识别。这个解释我觉得有一定道理,但同时也疑惑,人眼干不了计算机视觉就真的干不了吗?也许我举的这个例子和这篇文章关系不大,但对于底层的人眼视觉和计算机视觉的差异确实是需要研究的,看了文章的conclusion, 计算机视觉也许能突破人类视觉的瓶颈,但同时,它也会有自己的瓶颈。
Our findings suggest that human vision and computer vision may take both similar and different paths when learning to interpret images of the real world. Overall, while differences remain, foundation models trained on vision tasks start to align with low-level human vision, with DINOv2 showing the closest resemblance.
-
From Multimodal LLMs to Generalist Embodied Agents: Methods and Lessons
从多模态LLMs到通才具身智能体:方法和经验教训Author: Andrew Szot
Affiliation: Apple Georgia TechSpecifically, our focus lies in areas such as Embodied AI, Games, UI Control, and Planning
范围挺大的,目的在于拓展MLLM的应用领域,有时间看看
-
On the Consistency of Video Large Language Models in Temporal Comprehension
关于视频大语言模型在时间理解中的一致性Author: Minjoon Jung
Affiliation: National University of Singapore Seoul National University长视频中的事件与时间关联对齐,增强时间理解能力
-
Author: Hanxun Yu
Affiliation: 浙大 南航Inst3D-LMM可以同时处理多个3D场景理解任务,捕捉对象之间复杂的pairwise spatial relationships
-
DSPNet: Dual-vision Scene Perception for Robust 3D Question Answering
DSPNet:用于稳健 3D 问答的双视觉场景感知Author: Jingzhou Luo
Affiliation: 哈工大如题,双视觉场景感知,增强了3D场景理解的文本输出能力,有时间可以看看
-
Escaping Plato’s Cave: Towards the Alignment of 3D and Text Latent Spaces
逃离柏拉图的洞穴:走向 3D 和文本潜在空间的对齐Author: Souhail Hadgi
Affiliation: 巴黎综合理工学院3D和文本之间的研究
ours is the first work that helps to establish a baseline for post-training alignment of 3D uni-modal and text feature spaces, and helps to highlight both the shared and unique properties of 3D data compared to other representations.
这个得掌握一下baseline是什么
-
Author: Jie Tian
Affiliation: 华科解决目前生成的视频运动程度有限或表现出与文本条件冲突的不可控运动,文章中提出的separate stages还需要再了解一下
-
Functionality Understanding and Segmentation in 3D Scenes
3D 场景中的功能理解和分割Author: Jaime Corsetti
Affiliation: Fondazione Bruno Kessler University of Trento理解3D场景中的功能。比如任务为“打开吸顶灯”,具身智能体需要先定位电灯开关,而任务描述中没有明确提及该开关,因。因此需要一个模型来推理,识别感兴趣的对象。这里就需要对视图进行分割,理解。
-
Author: Alejandro Castañeda Garcia
Affiliation: Delft University of Technology提出一个无监督方法,从单个视频中估计已知连续控制方程的物理参数。对文章还需要再看看,不太理解。
-
Author: Ronghao Dang
Affiliation: 达摩院 浙大 同济提出一个评估基准(ECBench) 和一个评估系统(ECEval),用于评估LVLMs的具身认知能力
-
H-MoRe: Learning Human-centric Motion Representation for Action Analysis
H-MoRe:学习以人为本的运动表示以进行动作分析Author: Zhanbo Huang
Affiliation: Department of Computer Science and Engineering, Michigan State University以自监督的方式学习人体运动,以矩阵格式来表示每个身体点的绝对和相对运动
-
Are Images Indistinguishable to Humans Also Indistinguishable to Classifiers?
人类无法区分的图像是否也对分类器无法区分?Author: Zebin You
Affiliation: 人大高瓴这个和我上面提到的垃圾分类的例子不同。这里是指真实图像和生成图像的区分。人眼无法识别图片,那么分类器(classifiers)能否识别?可以仔细看看
-
Author: Xiaoqi Li
Affiliation: 北大在RGB图像上添加2D视觉提示,这些提示代表了所需的任务目标,例如末端执行器姿态和接触后所需的移动方向。
这个方法确实很有创意,要仔细看看 -
Author: Jian Wang
Affiliation: MPI Informatics & Saarland Informatics Campus侧重于多个可穿戴设备的跟踪和理解人体运动
-
Learning 4D Panoptic Scene Graph Generation from Rich 2D Visual Scene
从丰富的 2D 视觉场景中学习 4D 全景场景图生成Author: Shengqiong Wu
Affiliation: National University of Singapore Nanyang Technological University 浙大通过给2D视觉场景注释来增强4D场景学习,要关注如何实现这一方法。
Most importantly, we propose a 2D-to-4D visual scene transfer learning framework, where a spatial-temporal scene transcending strategy effectively transfers dimension-invariant features from abundant 2D SG annotations to 4Dscenes, effectively compensating for data scarcity in 4D-PSG.
-
DaReNeRF: Direction-aware Representation for Dynamic Scenes
DaReNeRF:动态场景的方向感知表示Author: Ange Lou
Affiliation: United Imaging Intelligence文章Abstract提到了当前方法是如何建模和渲染场景的,要补充这部分知识。
In response, we present a novel direction-aware representation (DaRe) approach that captures scene dynamics from six different directions.
从六个方向来捕捉场景动态,训练时间更少,性能更强
-
EventEgo3D: 3D Human Motion Capture from Egocentric Event Streams
EventEgo3D:来自以自我为中心的事件流的 3D 人体动作捕捉Author: Christen Millerdurai
Affiliation: MPI for Informatics, SIC Saarland University, SIC解决当前运动捕捉在弱光和快速运动情况下失效的问题
-
Author: Inhee Lee
Affiliation: Seoul National University在存在遮挡,图像裁剪,少样本和极其稀疏观测等示例中重建3D人体
-
Wonder3D: Single Image to 3D using Cross-Domain Diffusion
Wonder3D:使用跨域扩散将单张图像转换为 3DAuthor: Xiaoxiao Long
Affiliation: The University of Hong Kong提高图像到3D的生成质量、一致性、效率
-
Holodeck: Language Guided Generation of 3D Embodied AI Environments
Holodeck:语言引导生成 3D 具身 AI 环境Author: Yue Yang
Affiliation: University of Pennsylvania用户输入想要获得的场景,通过LLM来获取关于场景可能是什么样的基础知识和不同对象间的空间关系约束
-
Situational Awareness Matters in 3D Vision Language Reasoning
态势感知在 3D 视觉语言推理中很重要Author: Yunze Man
Affiliation: University of Illinois Urbana-Champaign情景感知
-
Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
睁大眼睛?探索多模态LLMs的视觉缺陷Author: Shengbang Tong
Affiliation: New York University FAIR, Meta UC Berkeley探究LLM在视觉能力的缺陷,很重要
-
Author: Xiaoqi Li
Affiliation: 北大侧重于控制机器人末端执行器
-
Author: Shuhuai Ren
Affiliation: 北大(1) a timestamp-aware frame encoder that binds visual content with the timestamp of each frame and (2) a sliding video Q-Former that produces a video token sequence of varying lengths to accommodate videos of various durations.
-
Author: Bo He
Affiliation: University of Maryland, College Park Meta University of Central Florida
以在线方式处理视频,把过去的视频信息存储在记忆库中,从而进行长期分析 -
Author: Leonhard Sommer
Affiliation: University of Freiburg Saarland University需要了解Category-Level后再来看这篇文章
-
ULIP-2: Towards Scalable Multimodal Pre-training for 3D Understanding
ULIP-2:迈向可扩展的多模态预训练以实现 3D 理解Author: Le Xue
Affiliation: Salesforce AI Research Stanford University不需要3D注释的多模态3D学习
-
Author: Maxime Zanella Ismail Ben Ayed
Affiliation: UCLouvain UMons ́ETS Montreal需要有相应基础再看
-
Author: Jiazhao Zhang
Affiliation: 北大The two sub-polices, namely corner-guided exploration policy and category-aware identification policy,,simultaneously perform by utilizing online fused 3D points as observation.
用于目标导航的策略设计
-
On the Benefits of 3D Pose and Tracking for Human Action Recognition
关于 3D 姿势和跟踪对人体动作识别的好处Author: Jathushan Rajasegaran
Affiliation: UC Berkeley Meta AI, FAIR分析运动轨迹/姿态
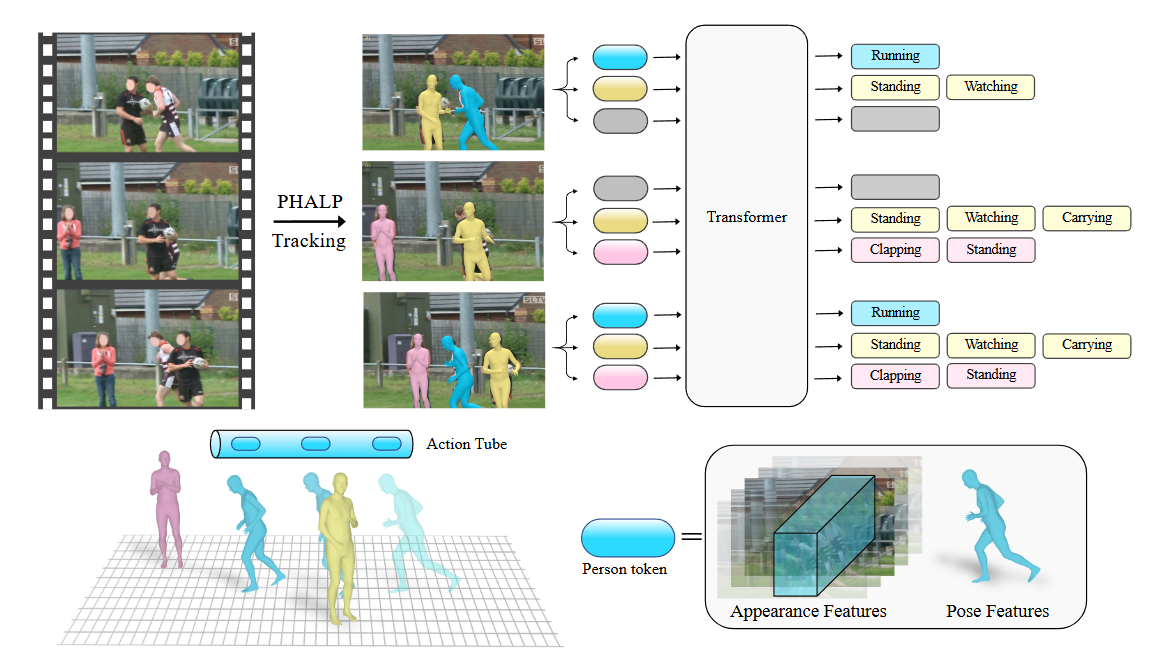
-
3D Human Pose Estimation via Intuitive Physics
通过直观的物理原理进行 3D 人体姿势估计Author: Shashank Tripathi
Affiliation: 普朗克研究所 荷兰阿姆斯特丹大学很感兴趣,通过 Center of Pressure (CoP) from the heatmap和SMPL body’s Center of Mass (CoM)来修正生成的三维人体模型
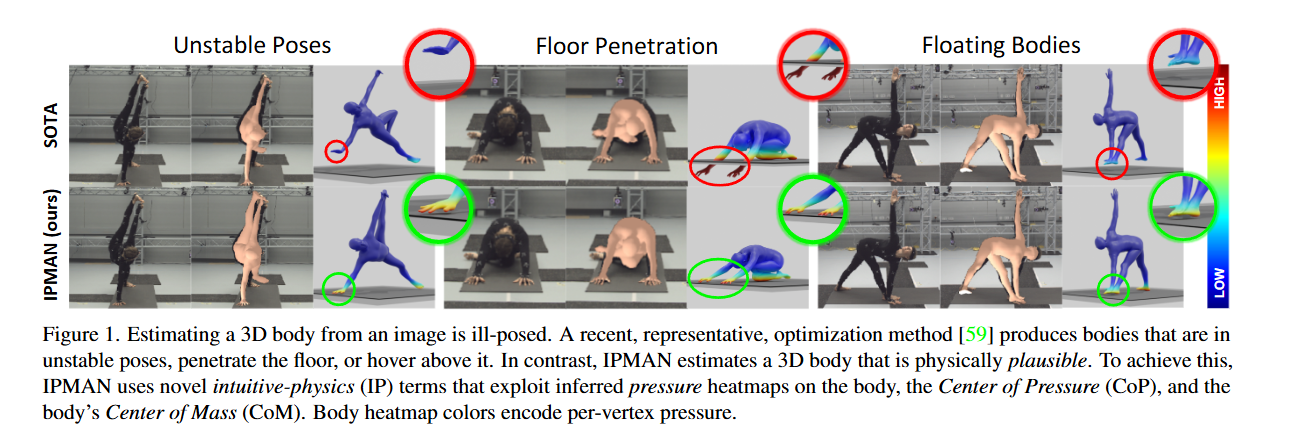
-
Panoptic Lifting for 3D Scene Understanding With Neural Fields
全景提升,用于神经场的 3D 场景理解Author: Yawar Siddiqui
Affiliation: Technical University of Munich Meta Reality Labs Zurich3D全景分割 ,理解
-
Adversarial Counterfactual Visual Explanations
对抗性反事实视觉解释Author: Guillaume Jeannere
Affiliation: University of Caen Normandie, ENSICAEN, CNRS, France需要有相应基础再看
-
Author: Seung Wook Kim
Affiliation: NVIDIA University of Toronto…3D场景生成

-
Author: Yu Sun
Affiliation: 哈工大5D: space, time, and identity 推理人物在摄像机和世界坐标系中随时间变化的 3D 轨迹

-
Author: Huiyu Gao
Affiliation: Australian National University需要有相应基础再看, 文章针对单目视频的在线三维场景重建
-
Author: Hanbyel Cho
Affiliation: Korea Advanced Institute of Science and Technology (KAIST), South Korea如题,对不同视角进行推理预测

ICCV2023
-
AerialVLN: Vision-and-Language Navigation for UAVs
AerialVLN:无人机的视觉和语言导航Author: Shubo Liu
Affiliation: Northwestern Polytechnical University University of Adelaide开发了一个3D模拟器,和组里的方向契合
-
Spatio-Temporal Domain Awareness for Multi-Agent Collaborative Perception
用于多智能体协作感知的时空域感知Author: Kun Yang
Affiliation: 复旦 Duke Kunshan University关注自动驾驶,多个智能体协同感知,也许是未来方向
-
DeePoint: Visual Pointing Recognition and Direction Estimation
DeePoint:视觉指向识别和方向估计Author: Shu Nakamura
Affiliation: Graduate School of Informatics, Kyoto University RIKEN侧重于手指指向的分析,具体方法需要仔细阅读
-
Author: Byeonghwi Kim
Affiliation: Yonsei University Gwangju Institute of Science and Technology如题,让机器人完成一个任务后,记住新的情景/环境,然后去进行下一个任务
-
Efficient Computation Sharing for Multi-Task Visual Scene Understanding
高效计算共享,实现多任务视觉场景理解Author: Sara Shoouri
Affiliation: University of Michigan侧重于计算效率
-
OxfordTVG-HIC: Can Machine Make Humorous Captions from Images?
OxfordTVG-HIC:机器可以从图像中制作幽默的标题吗?Author: Runjia Li
Affiliation: Torr Vision Group, University of Oxford KAUST幽默生成和理解,只是觉得标题好玩。
-
Author: Jiye Lee Hanbyul Joo
Affiliation: Seoul National University如题,但摘要中对方法的解释我有点不懂,后面可以仔细看看文章
-
Author: Xin Liu
Affiliation: Computer Vision Lab, Delft University of Technology Institute for Biodiversity and Ecosystem Dynamics, University of Amsterdam从静态关键帧预测未来物体位置,我觉得思路没问题,但是这种方法是否会有缺陷?(关注采样的策略)
-
PEANUT: Predicting and Navigating to Unseen Targets
PEANUT:预测和导航到看不见的目标Author: Albert J. Zhai, Shenlong Wang
Affiliation: University of Illinois at Urbana-Champaign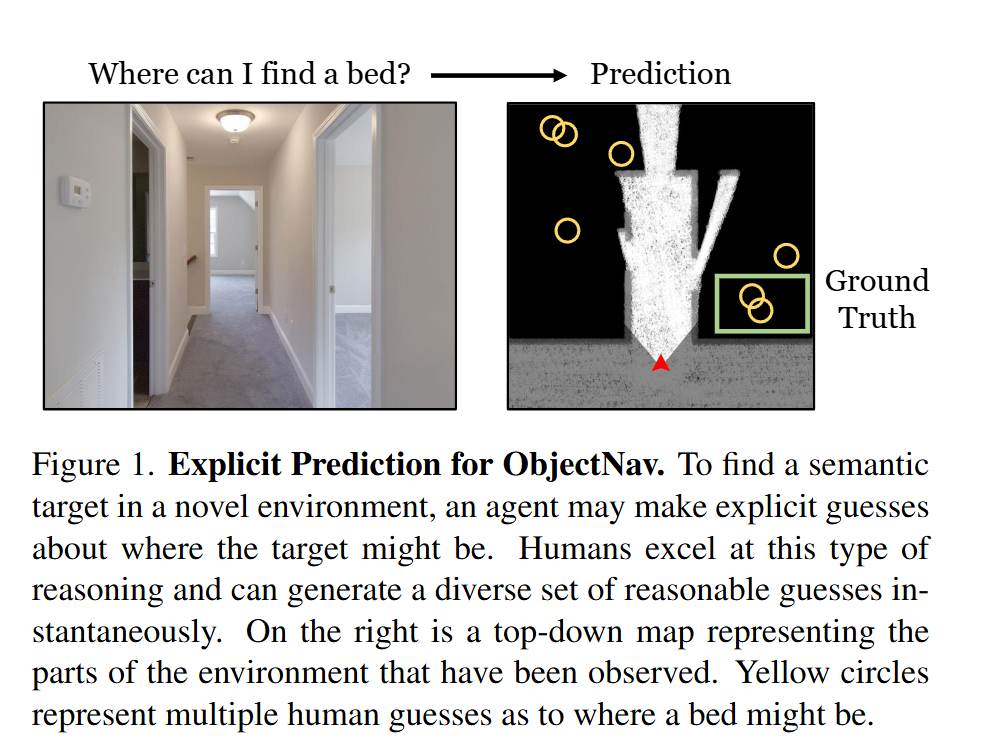
很有前景,但文章具体实现方法需要仔细分析
-
Author: Liang Xu
Affiliation: …运动生成,包含单人运动与多人运动
-
DG-Recon: Depth-Guided Neural 3D Scene Reconstruction
DG-Recon:深度引导神经 3D 场景重建Author: Jihong Ju
Affiliation: XR Labs, Qualcomm Technologies, Inc有点没看懂,有时间再看看(主要是一堆名词需要了解一下)
-
SLAN: Self-Locator Aided Network for Vision-Language Understanding
SLAN:用于视觉语言理解的自我定位辅助网络Author: Jiang-Tian Zhai
Affiliation: VCIP, CS, Nankai University Tencent Youtu Lab有点没看懂,有时间再看看
-
PoseFix: Correcting 3D Human Poses with Natural Language
PoseFix:使用自然语言校正 3D 人体姿势Author: Ginger Delmas
Affiliation: Institut de Robotica i Informatica Industrial, CSIC-UPC, Barcelona, Spain NAVER LABS Europe用自然语言纠正3D人体姿态/源姿态需要如何修改才能获得目标姿态
-
Author: Nikos Athanasiou
Affiliation: Max Planck Institute for Intelligent Systems, T ̈ubingen, Germany LIGM, ́Ecole des Ponts, Univ Gustave Eiffel, CNRS, France通过文本来合成3D人体运动,关注如何同时实现两个/多个动作,这个挺有前景的

-
Author: Levon Khachatryan
Affiliation: Picsart AI Resarch (PAIR) UT Austin SHI Labs @ Georgia Tech, Oregon & UIUC
In this paper, we introduce a new task, zeroshot text-to-video generation, and propose a low-cost approach (without any training or optimization) by leveraging the power of existing text-to-image synthesis methods (e.g. Stable Diffusion), making them suitable for the video domain
需要关注这个方法具有的缺点,也许是一个有很大潜力的方法
ECCV2024
-
Physics-Based Interaction with 3D Objects via Video Generation
通过视频生成与 3D 对象进行基于物理的交互Author: Tianyuan Zhang
Affiliation: MIT 斯坦福 哥伦比亚大学 康奈尔物理交互,很神奇,但难度很大
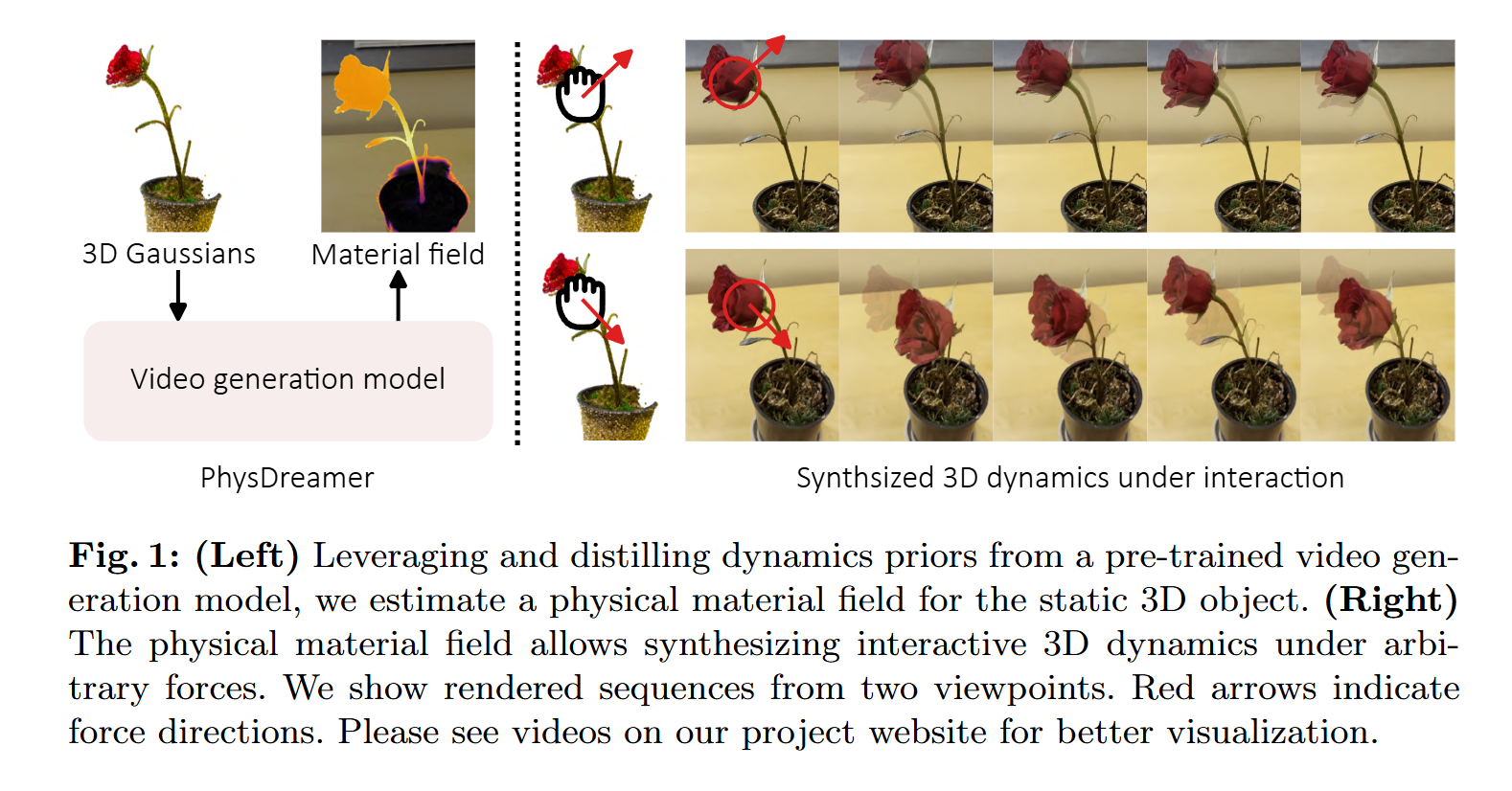
-
Author: Kashyap Chitta
Affiliation: University of Tübingen自动驾驶
-
Author: Benjin Zhu
Affiliation: MMLab, The Chinese University of Hong Kong3D场景理解,解决高分辨率占据预测的高内存成本问题
-
QUAR-VLA: Vision-Language-Action Model for Quadruped Robots
QUAR-VLA:四足机器人的视觉-语言-动作模型Author: Pengxiang Ding
Affiliation: 浙大设计了一个框架,融合感知、规划、决策
-
ScanReason: Empowering 3D Visual Grounding with Reasoning Capabilities
ScanReason:通过推理功能增强 3D 视觉基础Author: Chenming Zhu
Affiliation: The University of Hong Kong Shanghai AI Laboratory从隐式指令中推断人类意图
-
Large Motion Model for Unified Multi-Modal Motion Generation
用于统一多模态运动生成的大运动模型Author: Mingyuan Zhang
Affiliation: S-Lab, Nanyang Technological University, Singapore SenseTime Research, China运动生成
the objective of this work is to build a unified yet versatile foundation model for human motion generation, leveraging resources from a wide range of applications and achieving strong performance across the board.
还是挺困难的,需要仔细看看
-
PoseSOR: Human Pose Can Guide Our Attention
PoseSOR:人体姿势可以引导我们的注意力Author: Huankang Guan
Affiliation: Department of Computer Science, City University of Hong Kong人体姿态感知,并且将姿态知识作为方向性线索,来预测人类注意力将转向何处
-
Goldfish: Vision-Language Understanding of Arbitrarily Long Videos
金鱼:任意长视频的视觉语言理解Author: Kirolos Ataallah
Affiliation: King Abdullah University of Science and Technology Harvard University The Swiss AI Lab IDSIA, USI, SUPSI这个方法有时间得仔细看看
-
Author: Ahmad Khaliq
Affiliation: Queensland University of Technology, AustraliaVisual Place Recognition 通过分析图像来识别其在世界中的位置和环境的能力
可以再看看这篇论文
-
Real-time Holistic Robot Pose Estimation with Unknown States
未知状态的实时整体机器人姿态估计Author: Shikun Ban
Affiliation: 北大不需要知道机器人内部状态(我觉得是指关节角度,内部结构设计等)来进行机器人姿态估计,应该会应用与多机器人协作
-
Author: Feichi Lu
Affiliation: Department of Computer Science, ETH Zürich, Switzerland.
Max Planck Institute for Intelligent Systems, Germany
如题,侧重于人体近距离交互时的姿态识别 -
Author: Chengen Lai
Affiliation: 西电we create a synthetic multimodal counterfactual dataset (COCO-CF)
and propose a novel contrastive learning framework (COMO).提供一个数据集,通过对比来让模型学习
-
Author: Xinru Cui
Affiliation: 上交
a novel graph memory structure for navigation
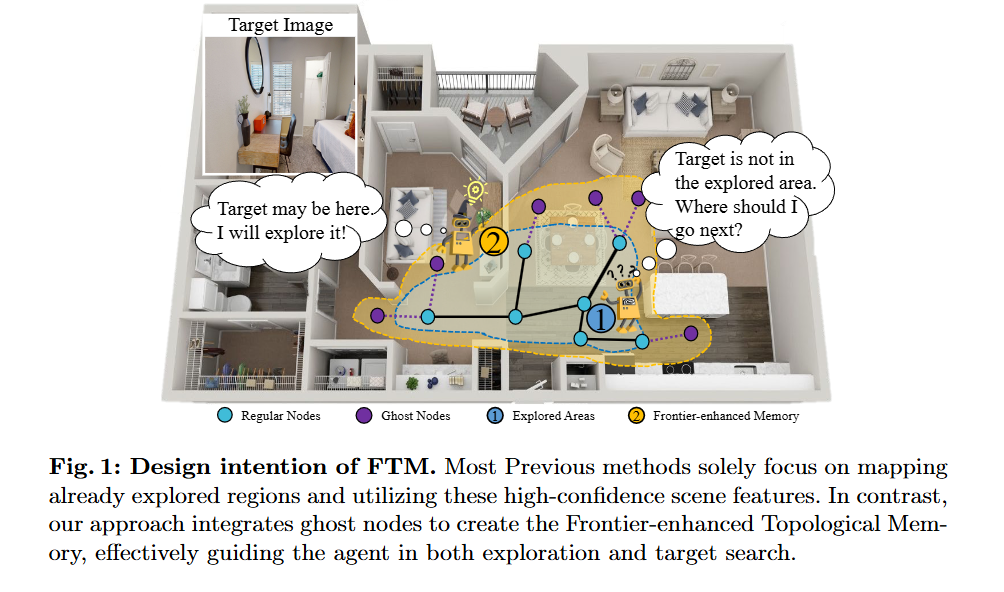
-
DeTra: A Unified Model for Object Detection and Trajectory Forecasting
DeTra:用于目标检测和轨迹预测的统一模型
Author: Sergio Casas
Affiliation:Waabi, University of Toronto
侧重于自动驾驶,使用激光雷达和高精度地图